 Kutatás vezetője: Varga Dániel
Kutatás vezetője: Varga Dániel
Rövid leírás: Kutatási projektünk keretében diszkriminatív mély tanulási modellek gradiens tájképét vizsgáltuk, illetve azt, hogy hogyan alakítható ki ez a tájkép a modell teljesítményének növelése érdekében. Sikerült kimutatnunk, hogy a gradiens regularizáció következetesen segíti a diszkriminatív hálózatok általánosítóképességét. Ezen hatás fokozottan érvényesül akkor, amikor kis adathalmazból kell a rendszernek tanulnia.
Kutatási projektünk keretében diszkriminatív mély tanulási modellek gradiens tájképét vizsgáltuk, illetve azt, hogy hogyan alakítható ki ez a tájkép a modell teljesítményének növelése érdekében.
Egy neurális háló felfogható egy folytonos, majdnem mindenhol differenciálható leképezésnek. A leképezés simaságát egy adott pontban a kimenet bemenet szerinti gradiensével jellemezhetjük. Ha a neurális hálózatok tanítása közben a rendszert arra kényszerítjük, hogy a tanító pontokban számolt gradiens kicsi legyen, akkor várhatóan az egész leképezés simább lesz. Ezen ötlet különféle formalizációit nevezzük gradiens regularizációnak.
Kutatásunk során számtalan gradiens regularizációs módszerrel kísérleteztünk, illetve elemeztünk. A különféle módszereket egy egységes matematikai keretben tárgyaltuk, melynek középpontjában a neurális háló logitjainak a bemenet szerinti Jacobi mátrixa áll. Ebben a megközelítésben több, látszólag különböző módszerről derültek ki mély kapcsolatok.
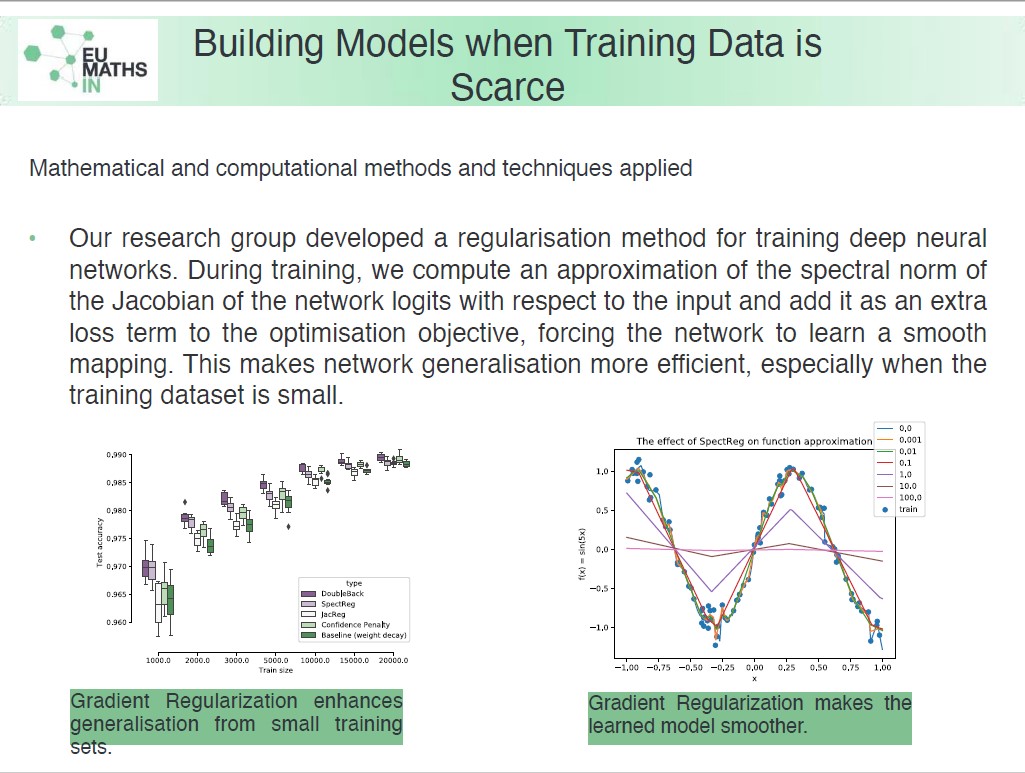
Sikerült kimutatnunk, hogy a gradiens regularizáció következetesen segíti a diszkriminatív hálózatok általánosítóképességét. Ezen hatás fokozottan érvényesül akkor, amikor kis adathalmazból kell a rendszernek tanulnia. A kevés adatból tanulás egy kifejezetten nehéz feladat neurális hálók számára, és ez a terület még nagyrészt felderítetlen, ezért eredményeinket ígéretesnek tartjuk.
Az irodalomban fellelhető több gradiens regularizációs változat elemzése mellett mi magunk is kidolgoztunk egy módszert, melyet Spectral Regularization-nek neveztünk. A neurális háló logit vektorára egy véletlen projekciót alkalmazunk 1 dimenzióra, majd kiszámoljuk ennek a bemenet szerinti gradiens vektorát. A tanítás során négyzetes hibával büntetjük a gradiens vektor hosszát. Módszerünkről kimuttuk, hogy jobban működik diszkriminatív hálók regularizálásában, mint más hasonló megközelítések.
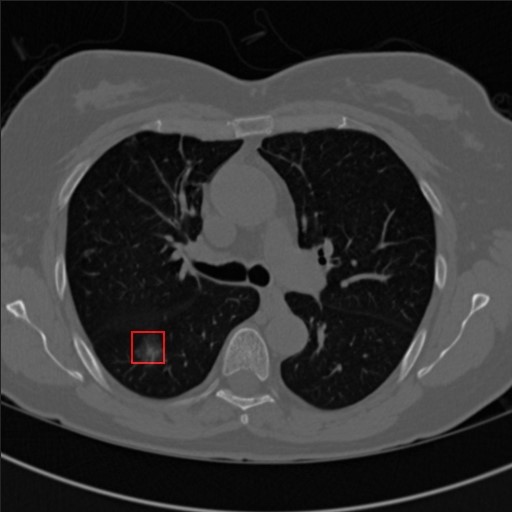
Módszerünket ipari partnerünkkel, a Medinnoscan-nel közösen dolgoztuk ki. A Medinnoscan tüdő CT felvételek alapján igyekszik meghatározni, hogy van-e rákos elváltozás, neurális hálózatok segítségével. Mivel ezen a területen rendkívül drága és lassú a tanító adatok gyűjtése, a partner számára kulcsfontosságú, hogy javítani tudja modelljét kevés adat mellett is. A Spectral Regularization algoritmust partnerünk kipróbálta és az első visszajelzések alapján kis javulást tapasztalt.
Munkánkból egy cikk készült, melyet 2019 februárjában a Theoretical Foundations of Machine Learning (http://tfml.gmum.net/) konferencián mutattunk be, és a Schedae Informaticae folyóiratban jelent meg.